Track language model usage and costs
This sample web application demonstrates how to use Dev Proxy to monitor and track LLM usage and costs.

Track language model usage and costs
Summary
Sample web app that demonstrates how to use Dev Proxy to monitor and track LLM usage and costs.
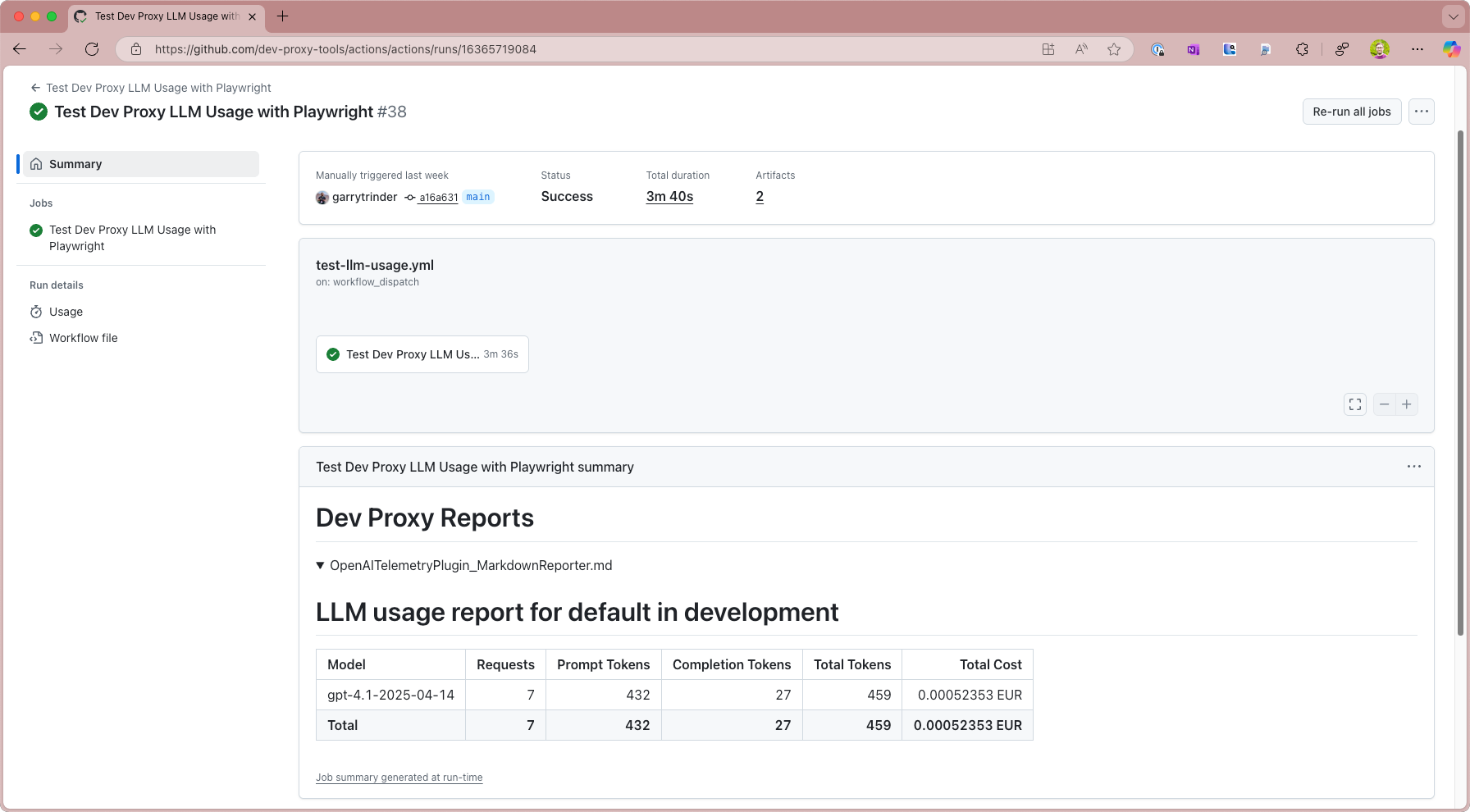
The sample showcases:
- LLM Cost Tracking: Monitor token usage and costs for OpenAI API calls
- Functional API Integration: Serve test data using CrudApiPlugin
- Latency Simulation: Add realistic delays to API responses
- VS Code Integration: Use Dev Proxy Toolkit for local development and testing
- End-to-End Testing: Playwright tests that verify the complete AI pipeline
- CI/CD Integration: GitHub Actions workflow with automated testing
Compatibility
![]()
Contributors
Version history
| Version | Date | Comments |
|---|---|---|
| 1.3 | February 4, 2026 | Updated to Dev Proxy v2.1.0 |
| 1.2 | January 18, 2026 | Moved config files to .devproxy folder |
| 1.1 | January 5, 2026 | Updated to Dev Proxy v2.0.0 |
| 1.0 | July 28, 2025 | Initial release |
Minimal path to awesome
- Get the sample:
-
Download just this sample:
npx gitload-cli https://github.com/pnp/proxy-samples/tree/main/samples/llm-usageor
-
Download as a .ZIP file and unzip it, or
-
Clone this repository
-
- Open the repository in Visual Studio Code
- Install the Dev Proxy Toolkit extension
Run locally (with local AI)
[!NOTE]
For Dev Proxy to simulate AI responses, you will need to run a local model on your machine which is accessible via an OpenAI API compatible endpoint, .e.g. Ollama. By default, this sample uses the Llama 3.2 model, change the
languageModel.modelproperty in the.devproxy/simulate-ai.jsonfile to use a different model. Ensure that the model is running before starting Dev Proxy.
- Start debug session in Visual Studio Code by pressing F5
- Wait for the process to complete
- Open the markdown file that is created in the root of the project to view the LLM usage report for the run.
Run locally (with cloud AI)
- Generate a fine-grained personal access token with
models:readpermission granted. - Update the
apiKeyvariable value injs/env.jswith your token. - Open Run and Debug panel and select 🧪 Run tests, cloud AI & local API debug configuration
- Start the debug session by pressing F5
- Wait for the process to complete
- Open the markdown file that is created in the root of the project to view the LLM usage report for the run.
Run in GitHub Actions
[!NOTE]
Enable GitHub Actions in your repository settings before running the workflow.
- Push the main branch to your GitHub repository
- Open a browser and navigate to your repository
- Open the Actions tab in your repository
- Trigger the Test Dev Proxy LLM Usage with Playwright workflow manually
- Wait for the workflow to complete
- View the usage report in the job summary
Help
We do not support samples, but this community is always willing to help, and we want to improve these samples. We use GitHub to track issues, which makes it easy for community members to volunteer their time and help resolve issues.
You can try looking at issues related to this sample to see if anybody else is having the same issues.
If you encounter any issues using this sample, create a new issue.
Finally, if you have an idea for improvement, make a suggestion.
Disclaimer
THIS CODE IS PROVIDED AS IS WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING ANY IMPLIED WARRANTIES OF FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR NON-INFRINGEMENT.